
Turning Social Data into Financial Opportunity.

How a Startup Predicted the Brexit Vote Accurately.
Brexit was a vote of epic proportions, it was highly contested and extremely volatile. It wasn’t just new rules and regulations, processes and procedures, the outcome had major effects on people and their lives. Needless to say, sentiments ran high. Not only for individuals but for the entire United Kingdom population. Many took to Twitter to voice their opinions and express their thoughts to the world. They let everyone know how they felt and what it meant to them. Doing so created unstructured data that was not only indicative of "mood of the moment", but also of voter outcome. There was enormous interest in knowing which way the vote might go given the short and long term financial impact.
Social media feeds have been routinely used to predict financial services outcomes. Thomson Reuters, Bloomberg, Citi and others use social feeds from hundreds of sites and platforms on a daily basis. They clean up the data, normalize it and present it in an easy to read and understand visual for subscribers to consume (incorporate in their financial decision-making process). Large enterprise have been at it for a while, whether it be investing in stocks, fiat or cryptocurrencies. They have sophisticated tools and hundreds of engineers working on various tasks to provide sentiment analysis to their subscribers.
I recently came across Convey, a startup founded by Cody Pawlowski and William Widjaja, UIUC alumni who used sentiment analysis to determine the outcome of Brexit. They put their AI and ML knowledge to good use and developed a tool that took into account social media Twitter feeds for Brexit and predicted the vote accurately.
Being a highly contested vote, people took to Twitter to freely express their sentiments. Which is what they mined to get to the bottom of the outcome. They used NLP to get the end result, forecasted by mining millions of the social media responses. They developed a computational linguistics system that measured the “positive” or “negative” tone of the Twitter data associated with Brexit, along with its relevance and intensity. This was achieved by using their own adaptation of modern NLP and ML methods which outperform industry alternatives.
For example, a tweet by @reliquitdraco saying “That's it, if we vote remain I'm moving to Spain #brexit” has positive sentiment towards Brexit, though traditional methods would likely register it as being negative, as they have no contextual awareness. Similarly, a tweet by @worldnoteurope states “blah blah blah blah. Sorry did you say something? Nobody believes a word you say anymore. #StrongerIn #brexit.” While this user is exhibiting praise towards staying in the EU, most classification systems would determine that they are speaking negatively about it. Their method involved using several varying search terms which were believed to be correctly representative of the voter pool; the most effective of which being “leave” and “stay”. Geo-targeting parameters were also set such that only relevant data was returned from search requests. By doing so, they obtained a dataset which was far broader and less biased than other available polling methods.
Some of these traditional polling biases include response bias, non-response bias, and coverage bias. Response bias emerges as a result of respondents answering dishonestly due to an unwillingness to admit unpopular attitudes. While many who are posting online still exhibit this psychology, it’s been discovered that in general, people are more honest online than in person [1]. Non-response bias occurs when respondents simply refuse to give their opinion on a subject. Convey’s technique avoids this bias altogether by using a passive listening approach rather than eliciting viewpoints. Lastly, coverage bias arises as a result of an increasingly limited medium for polling. Fewer people own landlines nowadays, and it has become more difficult for polling firms to garner cooperation from cellphone users. This is due to carrier expenses, plus the overall spammy nature of calling personal phones to elicit a response. As a result, pollsters offer incentives for these responses, introducing yet another form of bias. After collating the individual results generated from processing several million tweets, they plotted them on a graph with the Y-axis being the overall sentiment and the X-axis being time.
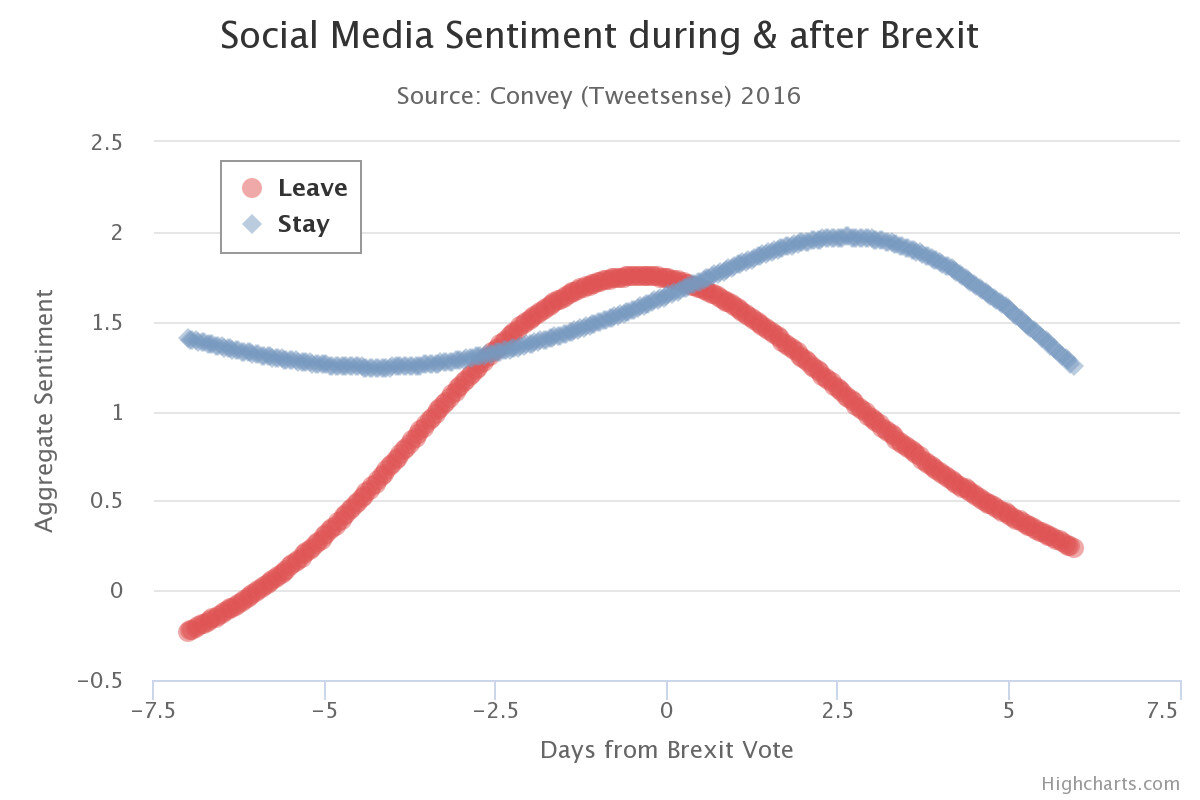
On the day of the vote, the sentiment for leaving and staying was 1.74% and 1.64%, respectively. These percentages construe that roughly 6% more people overall voted to leave. In actuality, the margin between leaving and staying was 3.8%. By calculating the percent error between these values, we find Convey’s method to be nearly 97.79% accurate. Many polling firms at the time had predicted an 85% likelihood of Britain remaining in the EU [2].
Interestingly, the sentiment towards leaving the EU mimics a sinusoidal function while the sentiment towards staying remains relatively the same throughout. From 2.5 days in advance to less than 1 day after the vote, it is shown that more voters prefer Britain to leave the EU. However, outside of this range, the sentiment towards Britain staying trounces that of it leaving. With proper analysis, one could deduce in advance that there is a strong likelihood of a Brexit outcome due to “leave” and “stay’s” opposing slopes.
Currently there are murmurs of Brexit vote going in for a reconsideration. With slowing economy few have started to see signs of a shift in public opinion. The opinion polls are buzzing again creating more data to mine. It remains to be seen if Convey is able predict the voter outcome accurately once again. As we know only time will tell. I wish them the very best in their endeavor.
References:
[1] Hancock, Jeff. “The future of lying.” TED. Sept. 2012. Lecture.
[2] “Who Said Brexit Was a Surprise?” The Economist, The Economist Newspaper, 24 June
2016, www.economist.com/blogs/graphicdetail/2016/06/polls-versus- prediction-markets.